
Segment positions itself as a Customer Data Infrastructure or CDI. What that actually means is that they see themselves as the glue that binds any and all customer data points in order to create a holistic view of all interactions of a company with a customer. They don’t limit themselves to web data or CRM data. Their solution aims to bridge & unify all existing data silos.
In order to do so Segment spans a series of areas:
1. Data collection
Starting a Segment implementation track starts with building a tracking plan. This means we’ll be looking which elements should be tracked, which metadata should be attached to each element (Segment calls this properties) and how and when to identify users together with their associated traits. Segment uses a specific syntax that consists of different commands to track events or identify users. As the term CDI insinuates Segment is a core infrastructural element. Therefore implementing Segment requires the work of developers. Where more classic data collection technologies such as Tag Management Systems focus on deploying marketing tags only by piggybacking on the existing infrastructure (such as a dataLayer), Segment’s focus goes way beyond that (and thus requires a different setup). Segment is capable of ingesting data from all kinds of sources such as websites, applications, databases, CRM’s, advertising platforms, payment systems, etc.
2. Quality assurance & control
As Segment’s objective is to collect data once, stitch it together & dispatch it to a series of applications, it’s rigorous when it comes to data quality. Segment comes with built-in quality assurance capabilities called protocols (think of the likes of Hub’Scan or ObservePoint). Protocols verify any incoming data points and compare it against the initial tracking plan and expected results. As soon as non-compliant elements are being ingested by Segment approval to process the data will be requested. Segment users can choose to allow these data points or to omit them from being passed on to the applications connected to Segment’s CDI.
3. Unification
Segment’s main objective, next to collecting clean data, is to ensure unification. Segment uses a userID using an identify method to track users & unify data across all of their interactions. This means that separate interactions on different platforms such as web, application & even call center can be stitched & attributed to a single user.
4. Data library building
Once data passes the QA & control procedures data is ingested in Segment’s data library or schema. This library is then used to dispatch data to any output application. This is now the collection of master data from which all other platforms & applications will be fed.
5. Data dispatching
From the data library additional applications can be connected. Think of things like analytics solutions (Google Analytics, Mixpanel, Amplitude, etc), CRM systems (HubSpot, Salesforce, ect), advertising platforms (Facebook, DoubleClick, Criteo, AppNexus, etc), Raw data storage (Redshift, Bigquery, Snowflake, etc) and many others.
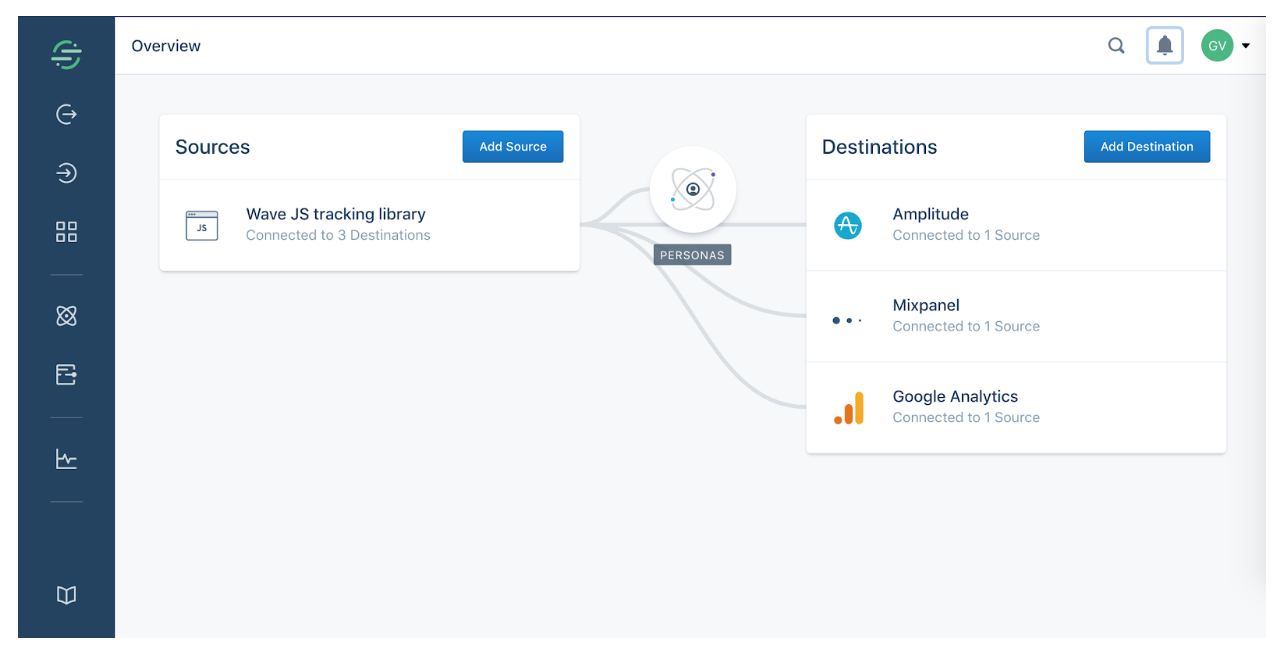
Even though this is a very short introduction and it only addresses a fraction of Segment’s capabilities, it’s clear that Segment is a new breed of products focused on building data pipelines that consolidate all data point around a single customer in order to derive actionable insights & put them into play. Are you looking for clean & unified data at user-level in order to feed systems that provide insights on the customer journey or build applications to enhance it, then Segment is your go-to platform.

Glenn Vanderlinden
| LinkedinThis email address is being protected from spambots. You need JavaScript enabled to view it.
