
De lancering van GA4 gaat niet van een leien dakje. GA4 is een significante verandering ten opzichte van de vorige versie van Google Analytics, Universal Analytics. De tool maakt gebruik van nieuwe features, datamodellering en rapportering die een significante leercurve heeft voor de meeste gebruikers. Daarbovenop ervaren veel gebruikers technische problemen met GA4, zoals datadiscrepancies, incorrecte tracking en vertraging in het verwerken van data. Deze issues leidden tot frustraties en bezorgdheid van gebruikers, die rekenen op correcte data om geïnformeerde beslissingen te maken. Eén van deze problemen is kardinaliteit.
Wat is kardinaliteit?
Kardinaliteit is het aantal unieke waarden die aan een dimensie hangen. GA4’s datamodel is gebaseerd op events, die een unieke identificator naar elk event sturen. Als een bepaald dataveld (of kolom) een hoge kardinaliteit heeft (d.w.z. een hoog aantal unieke waarden), kan dit leiden tot een hoog aantal unieke event IDs, wat op zijn beurt leidt tot vertraging in dataverwerking en discrepanties.
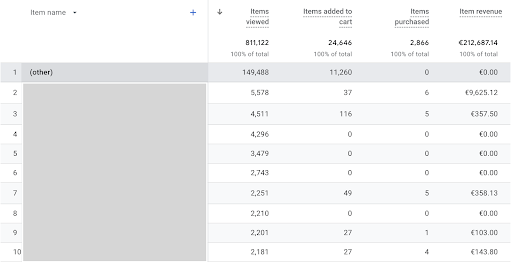
Om een oplossing te bieden voor deze dimensies met een hoge kardinaliteit, groepeert Google dimensies in een (overige) rij. Deze rij wordt verafschuwd onder marketeers en data-analysten. Bijvoorbeeld, als een GA4-property een hoge kardinaliteit heeft voor de dimensie “Artikelnaam”, die veel unieke waarden bevat op een ecommercewebsite, kan dit leiden tot een groot aantal unieke event IDs.
WIn het voorbeeld hieronder kan je zien hoe dit er in de praktijk uitziet: het aantal unieke event IDs die worden gegenereerd voor het event Items viewed en Items added to cart is te hoog om te verwerken in GA4. Daardoor wordt de dimensie Item name samengenomen in (other). Dit is suboptimaal voor correcte rapportering.
Wat zijn de oplossingen?
De verontwaardiging over dit kardinaliteitsprobleem toont aan dat het samendrukken van resultaten in één rij van gegevens één van de grootste problemen is van GA4 tot nu toe. Google heeft op dit moment nog geen oplossing gevonden om hoge kardinaliteitsdimensies te verhelpen in standaardrapporten. Voordat we een oplossing formuleren voor kardinaliteit, lijsten we de vier rapportagesoorten in GA4:
1. Standaardrapporten: GA4 heeft meerdere standaardrapporten die je kan raadplegen aan de linkerkant van het navigatiemenu. Deze rapporten zijn Acquisition, Engagement, Monetization, Retention, Demographics en Tech.
Standaardrapporten: GA4 heeft meerdere standaardrapporten die je kan raadplegen aan de linkerkant van het navigatiemenu. Deze rapporten zijn Acquisition, Engagement, Monetization, Retention, Demographics en Tech.
2. Verkenningen: Een verkenning kan direct gecreëerd worden via standaardrapporten bij het openen van het datakwaliteitslogo en te klikken op Create an exploration.
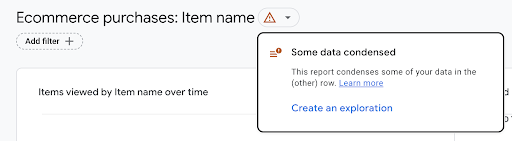
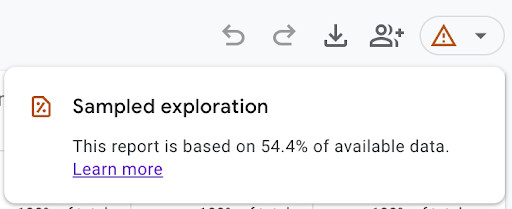
Deze optie creëert een Verkenning aan de hand van dezelfde query, met het laagste samplingsniveau. Dat wil zeggen dat in Verkenningen datasampling kan optreden, wat één van de fundamentele problemen was in Universal Analytics.
3. API: Je kan er uiteraard ook voor kiezen om je data direct te versturen naar een dashboardingtool zoals Looker Studio. Data versturen via de API is echter niet de beste optie om kardinaliteit te voorkomen, gezien je data geblokt kan worden door Google Analytics’ API quota. Supermetrics schreef over deze issue specifiek een interessant artikel.
Verkenningen en de API bieden dus het hoofd aan kardinaliteit, maar zijn geen oplossingen voor de fundamentele functionaliteit van een analytics-tool: precieze data verkrijgen die gebruikers geïnformeerde beslissingen doet nemen.
Dit brengt ons naar de laatste rapportagesoort die GA4 aanbiedt, zonder een 360 licentie aan te kopen:
4. BigQuery: Je GA4-property linken aan een BigQuery Export en dezelfde data verkrijgen in BigQuery lijkt momenteel de beste optie op kardinaliteit te voorkomen. BigQuery-GA4 data is niet onderheven aan datasampling en kardinaliteit, aangezien data op een andere manier wordt opgeslagen. De data wordt namelijk opgeslagen in een ruw formaat, wat betekent dat elk individueel event wordt opgeslagen als een aparte “record”, in plaats van geaggregeerd te worden in een vooraf gedefinieerde tabellen.
In conclusie, ook al is GA4 (momenteel nog) gratis, komt het met erg wat dataverwerkinglimitaties, wat er toe kan leiden dat je jouw data niet kan analyseren op de manier die jij wil. Om een ongesamplede dataset zonder kardinaliteitsproblemen te verkrijgen, zal je wellicht overwegen een cloudgebaseerd datawarehouse zoals BigQuery te gebruiken of te investeren in een 360-licentie, die beide extra kosten met zich mee kunnen brengen.

Robbe Desmyttere
| LinkedinDit E-mail adres wordt beschermd tegen spambots. U moet JavaScript geactiveerd hebben om het te kunnen zien.
